
Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
PROJECT III: WHITE PAPER
DOWNLOAD PDF VERSION: http://chimaboo.com/coursework/DATA73000/STANTON-WHITEPAPERDATA73000.pdf
“FROM ATOP TABLEAU, I CAN ALMOST SEE WHERE Y’ALL FROM”
FINAL PROJECT WHITE PAPER FOR DATA 73000: INTRODUCTION TO DATA VISUALIZATION
WRITER: Matthew Stanton ([email protected]), May 2023
SUMMARY
“So… Where Ya From? How New Yorkers Identify Their Roots” was inspired by previous work on measuring the educational cost of NYC’s “stop-and-frisk” era and the population changes in New York City due to Robert Moses’ transit infrastructure overhaul. It also drew inspiration from the author’s own neighborhood in Brooklyn, which is home to a diverse range of residents from various ethnic backgrounds.
The dataset used in the project was obtained from IPUMS USA, which provides U.S. census microdata. The dataset included a 1% sample from the 2021 U.S. Census for each of New York City’s five boroughs. However, due to limitations in the data, the project had to pivot from mapping ethnic demographics to focusing on how New Yorkers identify their roots when asked about their ancestry. Challenges faced during data cleaning and categorization, grouping and merging variables to create meaningful categories for analysis, allowed for a version of a Sankey diagram and other visualizations to represent the data.
Future iterations of the project should include a larger sample size and address the issues of undercounts and classification challenges. Additional insights were gained during the May 2023 poster session, including the discovery of potential misrepresentations of certain ethnic groups and the idea of using age as a projection of future growth by ethnic segments.
INTRODUCTION
The visualization “So… Where Ya From? How New Yorkers Identify Their Roots” (https://tabsoft.co/3q0xDHJ) was formed around the final project scope to formulate a research question, find a dataset to address that question and create at least three visualizations that provide insight into the question – ideally using Tableau software and techniques learned through various labs and readings offered in the Spring 2023 “Introduction to Data Visualization” course.
The inspiration for the topic grew from some initial project in the previous semester, “Measuring the Educational Cost of NYC’s Stop-And-Frisk Era (2005-2019)” (https://bit.ly/41PLdL7). The New York Police Department’s program of aggressively targeting specific communities and making temporary warrantless detentions had only recently dropped off from its annual high of 685,724 documented stops in 2011. Eventually curbed by U.S. District Court Judge Shira Scheindlin’s ruling in Floyd v. City of New York, the program was found unconstitutional and showed “significant evidence that the NYPD acted with deliberate indifference,” especially toward Hispanics (four times as likely as whites to be stopped) and Black New Yorkers (10 times more likely to be stopped).
Directly influential was Quinn Hood’s stop-and-frisk visualization (https://qhood01.github.io/nycSQF/), a fantastically utilitarian illustration of where, when, and on who the policy directly affected. At the time a research associate with Vera’s Greater Justice New York initiative, Hood worked primarily on quantitative analyses of the impact of New York’s recent bail reform legislation, and previously at the Data Collaborative for Justice at John Jay College where he helped produce reports focused on low-level enforcement in New York City.
Also of interest was the rapid population change in New York City following Robert Moses’ overhaul of the region’s transit infrastructure to prioritize automobile traffic to suburban satellite communities, the 1950s-1960s “white flight” that development enabled, and the resulting loss of municipal tax base by the and caused the financial crisis of 1975 (see Kim Phillips-Fein’s Fear City: New York’s Fiscal Crisis and the Rise of Austerity Politics, https://bit.ly/45iMehO).
Lastly, I was inspired by my current home neighborhood of Kensington in central Brooklyn, a mixture of Polish, Bangladeshi, Pakistani, Indian, Latin American, African-American, Orthodox Jewish (Hasidic), and Central Asian residents. According to data on one real estate website (https://bit.ly/3IskihE), one in four Kensington residents was born outside the United States. Here conversations in Yiddish and Spanish mix on sidewalks under loudspeakers broadcasting Islamic calls to prayer, and in each school day, a diverse range of parents walk their children to the same schools.
Almost immediately, the challenge of definitively mapping ethnic demographics to New York neighborhoods ran into problems of identity and granularity, as explained below. Limited by only how people declare themselves, and only tracking to the county (borough) level, the project question had to pivot from “Where do New Yorkers of various ethnic groups live?” to “How do New Yorkers identify their roots when asked about their ancestry?”
BACKGROUND
The starting place for the dataset came from IPUMS USA (https://usa.ipums.org/usa/), a freely available source tied to the Minnesota Population Center and University of Minnesota that “collects, preserves and harmonizes U.S. census microdata and provides easy access to this data with enhanced documentation.”
A .csv file was exported to include a 1% sample from the 2021 U.S. Census, from each of New York City’s five boroughs – Bronx County (ICPSR 0050), Kings County (Brooklyn) (ICPSR 0470), New York (Manhattan) (ICPSR 0610), Queens County (ICPSR 0810), Richmond County (Staten Island) (ICPSR 0850). Getting down to postal ZIP codes, community boards, or police precincts would have been preferred, but the available IPUMS data did not group that far down.
Using the most recently available data also came with a unique problem: NYC residents fled the city in 2020 amid the COVID-19 pandemic (https://www.unfpa.org/resources/technical-brief-implications-covid-19-census), and that cycle’s U.S. Census operations saw unprecedented procedural interference from Trump administration officials (see email from Office of the Director Chief of Staff Christa D. Jones, https://bit.ly/43bDecv).
Also, from a total population of roughly 8.4 million New Yorkers, a better 5% dataset should have contained 420,000 records – but in fact, the IPUMS data fell far short with only a 1% sample of 186,000 records. The working sample shrunk even more when accounting for the 42,000 records in which no response was given about ancestry. Such null responses were removed. A quick glance at the data showed some glaring omissions: No records cited ancestry of origin to Columbia, despite there being Columbian students currently enrolled in the CUNY Graduate Center Data Analysis and Visualization program.
Next, the closest option for tracking ethnicity was “ANCESTR1 – Ancestry, first response” within the Race, Ethnicity, and Nativity variables list. While the responses grouped by region were fairly specific (001 Alsatian, Alsace-Lorraine, 002 Andorran, 003 Austrian, 004 Tirolean, and so forth), they proved inconsistent overall. Some responses about individuals’ points of ancestry were vague or broad (“European” or “Slavic”), while others were based on racial self-identifications (“African-American” and “Afro-American,” separate from responses as “American,” “North American,” or even various lineages back to African countries). And what about Black Hispanics who were only recorded in one category? Or people of mixed heritage, be it by race or country?
Finally, the planned visualizations intended to represent a “coming to America” flow through the use of a Sankey diagrams, especially since such models were temporarily available in a pilot test from Tableau Public (https://tabsoft.co/3OugfW6). Unfortunately, early mockups showed the Sankey visualizations including Continent-Region-Country-Borough as flow marks would become too noisy to track, resulting in a riot of tiny lines instead of smoothly funneled paths. Groupings would instead need to be moved as footnotes shown in path tooltips.
PROPOSED SOLUTION
Initial data cleaning into bins was done in Python via a Google Collaboratory notebook (https://bit.ly/41ZkYlA), and saved back into a new Excel file. Variables for tracking Continent, Region, Country, and description of nationality were added. Some adjustments around “Continent” were made, treating Russia as its own unit outside “Europe” or “Asia,” and granting “West Indies” its own status as a “continent” outside North or Central America in order to highlight the statistical significance of Puerto Ricans, Dominicans, and Haitians in New York City’s population.
Further “bin cleaning” (in this case, treating base categories as bins) was done manually, deciding which variables could be merged. Some decisions were straightforward (“African-American” and “Afro-American” becoming one count), others arguably done for simplicity (“Mexican,” “Mexican American,” “Nuevo Mexicano,” and “Chicano/Chicana” all becoming one “from Mexico” tally), and some arbitrary (in which “British” and “English” were merged, but “Scottish” and “Welsh” were left as separate identities).
For the sake of completeness, ethnic-based “Lineage” was included on par with “Continents,” but the distinction raised an important issue: The responses were not objectively founded, as might be said about DNA testing results from such services such as Ancestry.com or 23andme.com. Instead, responses reflected how those surveyed expressed their desire to be seen as themselves. The given records in the data assumed the person’s chosen priority self-identity, though membership of one group might imply inclusion in other hierarchies of race, region, or continent. (Interestingly, though many respondents cited their familial country of origin as “USA,” only one U.S. state saw people report claims of direct origin: Texas.)
Both of the core problems – small data sample size and “race versus place” classifications – would need to be informed to the user before sharing any graphic visualizations – a grossly inelegant solution. A better (and future) presentation of these visualizations should be based on a much larger sample to reach the 5% minimum or, ideally, even larger. An alternative would have been to find exports of different sample cases and repeat the binning process, though issues of duplication would need to have been filtered out.
Once the initial Sankey diagram was created, adding additional views of the same data – bar charts, pie charts, treemaps, bubbles, and global mapping – were tested for inclusion in the final narrative package. Photo illustrations and light-hearted descriptions of boroughs were intended as visual cues to help distinguish what otherwise could have been visually too similar charts from Tableau.
The global map visualization presented its own problems. Records based on classifications that did not track to geographically defined countries – all Lineages such as “Hispanic” or “Asian,” broad regional designations such as “Northern European,” and stateless labels such as “Palestinian” or “Assyrian” – were dropped from the mapped counts.
Also, the United Kingdom created a significant misrepresentation. The combined points of origin should have shown 12,358 records, but since the dataset tracked “England,” “Scotland,” and “Wales” separately, no data was paired with the map’s parameters for the U.K. The solution seems simple: Manually add “United Kingdom” as records from the sum of England+Scotland+Wales tallies, and then either include or exclude on each visualization (see https://tabsoft.co/3MJp2BY for such a model). However, the Tableau Public Sankey diagram could not be made to exclude the redundant U.K. data, meaning the already significant England counts would be double represented. The lesser evil was to exclude the U.K. count from the map and add an annotation (another awful compromise). Hopefully, future implementations of the Sankey diagram model in Tableau will include full functionality to better tailor what data can be shown or excluded as needed.
CONCLUSION
The final visualization evolved from the pin-up session to remove less compelling visualizations, revise other explainer data, and add in the missing city-wide treemap illustration.
Two critical additions arose during the poster session on May 15, 2023.
First, something that confused me in the dataset was the high proportion of Germans noted in the points of origin. I had heard a great many Germans died in the PS General Slocum steamboat disaster in the East River back in 1904 (https://bit.ly/3Os2vLi). Still, my popular notions about European ancestry in New York were dominated more by the Italians, the Irish, and even the original founding English and Dutch.
And where were the Jews? According to the decade-old Jewish Community Study of New York by the UJA-Federation of New York (https://bit.ly/3OB82PE), more than 1 million Jews should have been included in the U.S. Census – the largest such demographic community in the United States. For New Yorkers, one would expect responses not just identifying people as Jewish, but in lineages of Ashkenazi Jews, Sephardic Jews, and the Hasidic subculture.
IPUMS USA data tends to be unhelpful regarding religious data. Observers at the poster session helped point out the structure of the question about ancestry, “What is your country of origin,” may have masked these hundreds of thousands of Jews in tallies for Germans, Russians, Romanians, Austrians, Hungarians, and other Central and Eastern European countries. (For more on the topic, see After They Closed the Gates: Jewish Illegal Immigration to the United States, 1921-1965 by Libby Garland, https://bit.ly/3Otk5yI).
Second, an additional facet of the data was to include age as a projection of future growth by ethnic segments. By noting which ethnic groups had a younger median age, one could project those groups promised to have a higher growth rate if other factors remained equal. During the poster session, I found Nuraly Soltonbekov’s “The Case for More Immigration” (https://tabsoft.co/45g28JL) seized on that very idea but on a nationwide level for the whole United States. His method of visualizing deaths and births, and supplementing gaps in population growth through immigration, can easily be filtered to apply to just New York City’s five boroughs – a new project to work on over the summer.
PROJECT III: Welcome to New York City… So, Where Ya From? (Pin-up Draft)

New York is the “crossroads of the world,” but among today’s residents, where did everyone come from? Or rather, how do they identify their roots when asked about their “ancestry,” either as newly arrived immigrants, first gen natives, or Gotham’s Old Guard of past generations? And, whether from far-off lands or just over the bridge-and-tunnel borders, where did they settle down amid the city’s constant change?
Looking at the most recent data to answer these questions poses two challenges. First, when using U.S. Census data from IPUMS USA, the most recent collection available – a sample excerpt from the 5-county population of NYC, about 144,000 records – was taken as NYC residents fled the city amid the COVID-19 pandemic, coupled with unprecedented procedural interference from Trump administration officials.
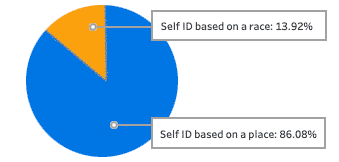 Second, there is the “Race Versus Place” issue. The census data about ancestry was voluntary, with only a portion of those surveyed responding with answers. Even worse from a data collection standpoint, some responses about point of ancestry were vague (“Asian” or “Slavic”), while others were based on racial self-identifications (“African-American” and “Afro-American,” separate from responses as “American,” “North American,” or even various lineages back to African countries). And what about Black Hispanics who were only recorded in one category? Or people of mixed heritage? For the sake of completeness, ethnic-based “Lineage” is included on par with “Continents” in the graphs below. The responses are not scientific; they reflect how those surveyed expressed their desire to be seen as themselves…
Second, there is the “Race Versus Place” issue. The census data about ancestry was voluntary, with only a portion of those surveyed responding with answers. Even worse from a data collection standpoint, some responses about point of ancestry were vague (“Asian” or “Slavic”), while others were based on racial self-identifications (“African-American” and “Afro-American,” separate from responses as “American,” “North American,” or even various lineages back to African countries). And what about Black Hispanics who were only recorded in one category? Or people of mixed heritage? For the sake of completeness, ethnic-based “Lineage” is included on par with “Continents” in the graphs below. The responses are not scientific; they reflect how those surveyed expressed their desire to be seen as themselves…
^ View the above graphic on Tableau Public
^ View and expand the above graphic on Tableau Public | NOTE: The United Kingdom does not appear counted on the above map since England, Scotland, and Wales were tracked as separate ancestral identities in the source data. For U.K. metrics, see the Western Europe tallies below.
^ View and expand the above graphic on Tableau Public
Diversity By Borough
Finally, the following treemaps show the relative populations claimed by local New Yorkers in the IPUMS USA 2021 sample of 143,859 records.


^ View and expand the above graphic on Tableau Public

^ View and expand the above graphic on Tableau Public

^ View and expand the above graphic on Tableau Public

^ View and expand the above graphic on Tableau Public

^ View and expand the above graphic on Tableau Public
Who Cares Where Ya From? Does It Matter?
The impact of peoples’ heritage on New York City can be a blessing and a curse. Of the original IMPUS USA data pull, nearly 30% – or 42,098 – lacked any reported ancestry information. Ethnic identities, and especially racial ones, are social constructs with histories of fluid definition at best. Some may see “Where ya from?” in the same offensive light as asking BIPOC people, “What are you?”
But yeah, it matters.
On the bright side, New York City’s cultural diversity brings together a vast array of foods, fashions, and ideas. The iconic food truck industry alone and glutton magnets like Smorgasburg should be reason enough to celebrate the broad palate found across the five boroughs.
On the dark side, cultural and racial identities have an obvious history as excuses for inequalities, disparities, intolerance, and violence. For example, at the height of the New York Police Department’s “stop-and-frisk” policy for cases logged by police in 2011, a Hispanic man was four times as likely to be subjected to a stop as a white man, while a Black man was 10 times more likely to be stopped. According to quarterly analysis of NYPD records by the New York Civil Liberties Union, of the more than 685,700 “stop-and-frisk” encounters logged by police that year, 12% led to some form of criminal charges (possession of marijuana, prior outstanding warrants, or possession of a weapon). The remaining 88% of those stopped were completely innocent of any wrongdoing, but records of such stops could be used as “predictive guilt” in future legal matters.
But on the bright side… did I mention Smorgasburg?
Recent Comments